
Nedávny dokument z LG AI Research naznačuje, že údajne „otvorené“ súbory údajov používané na výcvik modelov AI môžu ponúkať falošný zmysel pre bezpečnosť – zistenie, že takmer štyri z piatich súborov údajov o AI označených ako „komerčne použiteľné“ v skutočnosti obsahujú skryté právne riziká.
Takéto riziká siahajú od zahrnutia nezverejneného materiálu autorských práv po obmedzujúce licenčné podmienky zakopané hlboko v závislosti na súbore údajov. Ak sú zistenia papiera presné, spoločnosti, ktoré sa spoliehajú na verejné súbory údajov, možno bude musieť prehodnotiť svoje súčasné potrubia AI alebo riskovať právne vystavenie sa po prúde.
Vedci navrhujú radikál a potenciálne kontroverzný Riešenie: Agenti na dodržiavanie predpisov založených na AI schopní skenovať a audity histórie údajov rýchlejšie a presnejšie ako ľudskí právnici.
Papier uvádza:
„Tento dokument sa zasadzuje za to, že právne riziko súborov údajov o výcviku AI nemožno určiť výlučne preskúmaním podmienok na úrovni povrchu; Dôkladná, end-to-end analýza redistribúcie súborov údajov je nevyhnutná na zabezpečenie dodržiavania predpisov.
„Pretože takáto analýza je mimo ľudských schopností vďaka svojej zložitosti a mierke, agenti AI môžu túto medzeru preklenúť tým, že ju vedie s väčšou rýchlosťou a presnosťou. Bez automatizácie zostávajú kritické právne riziká do značnej miery nepreskúmané, čo ohrozuje etický vývoj AI a regulačné dodržiavanie.
„Naliehame na výskumnú komunitu AI, aby uznala právnu analýzu end-to-end ako základnú požiadavku a aby prijala prístupy zamerané na AI ako životaschopnú cestu k škálovateľnému dodržiavaniu súladu údajov.“
Pri skúmaní 2 852 populárnych súborov údajov, ktoré sa javili ako komerčne použiteľné na základe ich individuálnych licencií, automatizovaný systém vedcov zistil, že iba 605 (okolo 21%) bolo v skutočnosti právne bezpečných pre komercializáciu, keď boli všetky ich komponenty a závislosti vysledované
Ten nový papier má názov Neverte licencie, ktoré vidíte-dodržiavanie súladu údajov vyžaduje masívne sledovanie životného cyklu poháňaného AI v mierkea pochádza od ôsmich vedcov vo výskume LG AI.
Práva a krivdy
Autori zvýrazňujú výziev Tvárou voči spoločnostiam, ktoré sa posúvajú vpred s rozvojom AI v čoraz neistejšom právnom prostredí – pretože bývalé akademické „spravodlivé použitie“ okolo školenia údajov o súprave ukladá zlomenému prostrediu, v ktorom je právna ochrana nejasná a bezpečný prístav už nie je zaručený.
Ako jedna publikácia zdôraznil Spoločnosti sa v poslednej dobe stávajú čoraz viac defenzívne o zdrojoch svojich údajov o odbornej príprave. Autor Adam Buick Komentáre*:
‚(Zatiaľ čo) OpenAI zverejnil hlavné zdroje údajov pre GPT-3, dokument predstavujúci GPT-4 odhalený iba to, že údaje, na ktoré bol model vyškolený, boli zmesou „verejne dostupných údajov (napríklad internetových údajov) a údajov licencovaných od poskytovateľov tretích strán“.
„Motivácie tohto prechodu od transparentnosti neboli vývojármi AI v žiadnom osobitnom vyjadrení, ktorí v mnohých prípadoch vôbec nevysvetlili.
„OpenAi opodstatnil svoje rozhodnutie nezverejniť ďalšie podrobnosti týkajúce sa GPT-4 na základe obáv týkajúcich sa„ konkurenčného prostredia a bezpečnostných dôsledkov rozsiahlych modelov “, bez ďalšieho vysvetlenia v správe.“
Transparentnosť môže byť nemilosrdným pojmom – alebo jednoducho mylným; Napríklad vlajková loď Adobe Hasič Generatívny model, vyškolený na údaje o zásobe, ktoré mali Adobe práva na využitie, údajne ponúkli zákazníkom ubezpečenie o zákonnosti ich používania systému. Neskôr, niektorí objavili sa To, že Firefly Data Pot sa stal „obohatenými“ o potenciálne údaje z autorských práv z iných platforiem.
Ako my Diskutované začiatkom tohto týždňaExistujú rastúce iniciatívy určené na zabezpečenie dodržiavania licencií v súboroch údajov, vrátane tých, ktoré budú zoškrabať iba videá z YouTube s flexibilnými licenciami Creative Commons.
Problém je v tom, že licencie samy osebe môžu byť chybné alebo omylom, ako naznačuje nový výskum.
Preskúmanie súborov údajov o otvorenom zdroji
Je ťažké vyvinúť hodnotiaci systém, ako je napríklad súvislosť autorov, keď sa kontext neustále mení. Preto sa v dokumente uvádza, že systém súladu údajov Nexus Data Duwork je založený na „rôznych precedensoch a právnych dôvodoch v tomto okamihu“.
Nexus využíva agent poháňaný AI s názvom Automatické spojenie pre automatizované dodržiavanie údajov. Automatické kompliment sa skladá z troch kľúčových modulov: navigačný modul pre prieskum webu; modul otázok (QA) pre extrakciu informácií; a bodovací modul na posúdenie právneho rizika.
Automatické kompliment sa začína webovou stránkou poskytovanou používateľom. AI extrahuje kľúčové podrobnosti, vyhľadáva súvisiace zdroje, identifikuje licenčné podmienky a závislosti a priraďuje skóre právneho rizika. Zdroj: https://arxiv.org/pdf/2503.02784
Tieto moduly sú poháňané doladenými modelmi AI, vrátane Exaone-3.5-32b-Inštrukcia Model, trénovaný na syntetické a ľudské údaje. Automatické kompliment tiež používa databázu na výsledky ukladania do vyrovnávacej pamäte na zvýšenie účinnosti.
Automatické kompliment začína používateľskou adresou URL poskytovanú používateľom a zaobchádza s ňou ako s koreňovou entitou, hľadá svoje licenčné podmienky a závislosti a rekurzívne sleduje prepojené súbory údajov na vytvorenie grafu závislosti na závislosti od licencie. Akonáhle sú všetky pripojenia mapované, vypočíta skóre dodržiavania predpisov a priraďuje klasifikácie rizika.
Rámec dodržiavania údajov uvedený v novej práci identifikuje rôzne† typy entít zapojených do životného cyklu údajov vrátane súbory údajovktoré tvoria základný vstup pre výcvik AI; softvér na spracovanie údajov a modely AIktoré sa používajú na transformáciu a využívanie údajov; a Poskytovatelia služieb platformyčo uľahčuje spracovanie údajov.
Systém holisticky hodnotí právne riziká zvážením týchto rôznych subjektov a ich vzájomných závislostí a presúva sa za hodnotenie licencií údajov o dátových súboroch tak, aby zahŕňal širší ekosystém komponentov zapojených do vývoja AI.
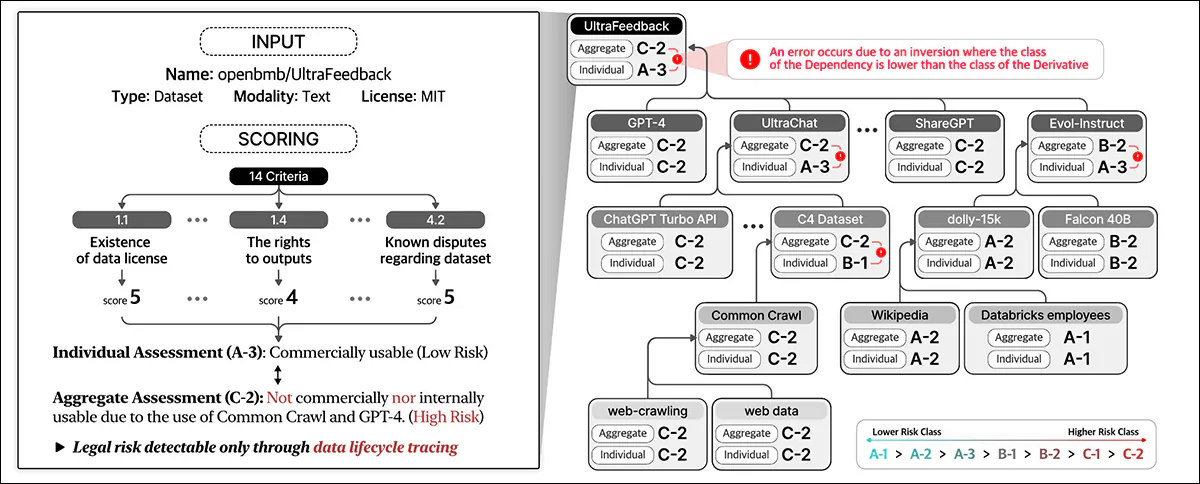
Dodržiavanie údajov hodnotí právne riziko v celom životnom cykle údajov. Priradí skóre na základe podrobností o súbore údajov a na 14 kritériách, klasifikáciu jednotlivých subjektov a agregáciu rizika medzi závislosťami.
Školenie a metriky
Autori extrahovali adresy URL z najlepších 1 000 najviac zložených súborov údajov na objímanie tváre, náhodne subplementov 216 položiek, aby predstavovali testovaciu súpravu.
Exaone model bol doladený Na vlastnom súbore údajov autorov s modulom navigacie a modulom na odpovedanie na otázky pomocou syntetické údajea bodovací modul s použitím údajov označených ľudskými.
Štítky pozemnej pravidiel vytvorilo päť právnych expertov vyškolených najmenej 31 hodín v podobných úlohách. Títo ľudskí odborníci manuálne identifikovali závislosti a licenčné podmienky pre 216 testovacích prípadov, potom agregovali a vylepšili svoje zistenia prostredníctvom diskusie.
S trénovaným, ľudským kalibrovaný Chatgpt-4o a Zmätok Pro, najmä viac závislosti bolo objavených v licenčných podmienkach:
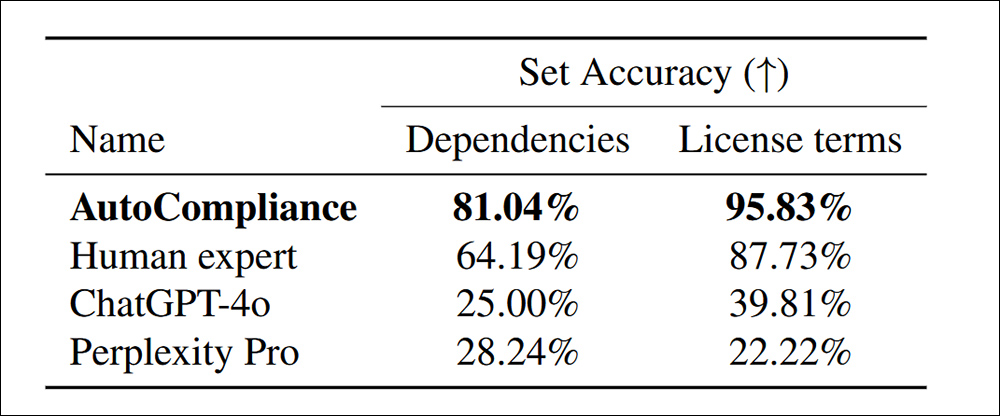
Presnosť pri identifikácii závislostí a licenčných podmienok pre 216 súborov údajov o hodnotení.
Papier uvádza:
„Automatickliance významne prevyšuje všetkých ostatných agentov a ľudských odborníkov, pričom v každej úlohe dosiahne presnosť 81,04% a 95,83%. Naopak, Chatgpt-4o and Relexity Pro vykazujú relatívne nízku presnosť pri zdrojových a licenčných úlohách.
„Tieto výsledky poukazujú na vynikajúci výkon automatického komplexu, demonštrujú jej účinnosť pri riešení oboch úloh s pozoruhodnou presnosťou a zároveň naznačujú značnú medzeru medzi modelmi AI a ľudským odborníkom v týchto oblastiach.“
Pokiaľ ide o účinnosť, prístup automatického dopĺňania trval iba 53,1 sekundy, na rozdiel od 2 418 sekúnd na ekvivalentné ľudské hodnotenie pri rovnakých úlohách.
Ďalej, hodnotiaci beh stojí 0,29 USD v porovnaní s 207 USD pre ľudských odborníkov. Malo by sa však poznamenať, že je to založené na prenájme uzla GCP A2-MegagPU-16GPU mesačne za sadzbu 14 225 dolárov mesačne-čo znamená, že tento druh nákladovej efektívnosti súvisí predovšetkým s veľkou činnosťou.
Vyšetrovanie
Pre analýzu vedci vybrali 3 612 súborov údajov kombinujúcich 3 000 najviac zložených súborov údajov z Hugging Face so 612 dátovými súbormi z roku 2023 Iniciatíva na pôvodné údaje.
Papier uvádza:
„Od 3 612 cieľových subjektov sme identifikovali celkom 17 429 jedinečných subjektov, kde 13 817 subjektov sa javilo ako priame alebo nepriame závislosti cieľových subjektov.
„Za našu empirickú analýzu považujeme za entitu a jej graf závislosti od licencie, aby mal jedinú vrstvovú štruktúru, ak entita nemá žiadne závislosti a viacvrstvovú štruktúru, ak má jednu alebo viac závislostí.
„Z 3 612 cieľových súborov údajov malo 2 086 (57,8%) viacvrstvové štruktúry, zatiaľ čo ďalších 1 526 (42,2%) malo jednovrstvové štruktúry bez závislostí.“
Dátové sady autorských práv možno prerozdeliť iba s právnou právomocou, ktorá môže pochádzať z licencie, výnimiek z autorských práv alebo zmluvných podmienok. Neoprávnené prerozdelenie môže viesť k právnym dôsledkom vrátane porušenia autorských práv alebo porušenia zmluvy. Preto je nevyhnutná jasná identifikácia nesúladu.
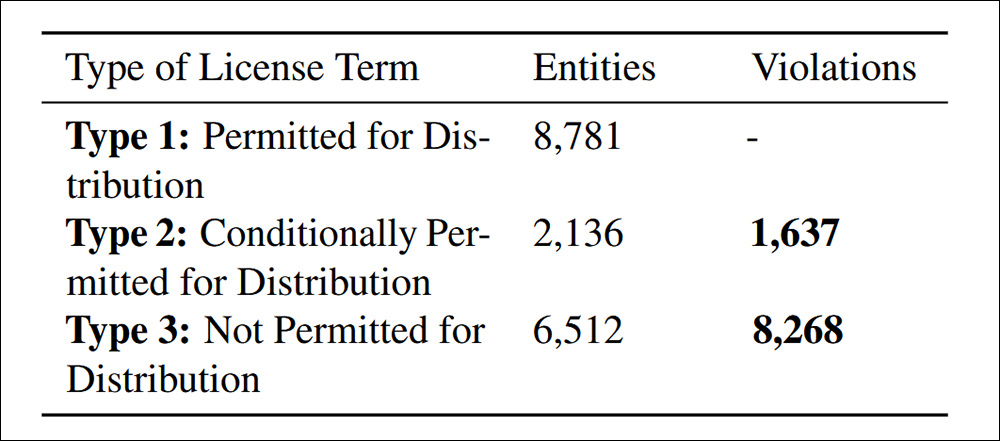
Porušenie distribúcie nájdené podľa citovaného kritéria príspevku 4.4. dodržiavania údajov.
Štúdia zistila, že 9 905 prípadov nedodržiavania redistribúcie súborov údajov, rozdelených do dvoch kategórií: 83,5% bolo za licenčných podmienok výslovne zakázaných, čím sa prerozdelilo jasné právne porušenie; a 16,5% zahŕňalo súbory údajov s protichodnými licenčnými podmienkami, kde bolo teoreticky povolené redistribúcia, ale ktoré nespĺňali požadované podmienky, čím sa vytvorilo právne riziko po prúde.
Autori pripúšťajú, že kritériá rizika navrhnuté v Nexus nie sú univerzálne a môžu sa líšiť v závislosti od jurisdikcie a aplikácie AI a že budúce vylepšenia by sa mali zamerať na prispôsobenie sa zmene globálnych predpisov pri zdokonaľovaní právneho preskúmania založeného na AI.
Záver
Je to prolix a do značnej miery nepriateľský papier, ale rieši pravdepodobne najväčší retardujúci faktor pri súčasnom prijatí AI v priemysle – možnosť, že zjavne „otvorené“ údaje neskôr budú nárokovať rôzne subjekty, jednotlivci a organizácie.
Podľa DMCA môže porušenia legálne znamenať masívne pokuty na a na prípad základ. Ak sa porušenia môžu stretnúť s miliónmi, ako v prípadoch, ktoré zistili vedci, je potenciálna právna zodpovednosť skutočne významná.
Okrem toho spoločnosti, ktoré je možné dokázať, že ťažili z údajov, nemôžu (ako obvykle) Nárokujte nevedomosť ako výhovorku, prinajmenšom na vplyvnom americkom trhu. V súčasnosti nemajú žiadne realistické nástroje, s ktorými môžu preniknúť z labyrintových dôsledkov pochovaných v údajne otvorených zdrojových licenčných zmluvách o súbore údajov.
Problém pri formulovaní systému, ako je napríklad Nexus, je v tom, že by bol dosť náročný na to, aby ho kalibroval na základe štátu vo vnútri USA alebo základom na národ v EÚ; Vyhliadka na vytvorenie skutočne globálneho rámca (druh „interpolu pre pôvod údajov“) je oslabená nielen protichodnými motívmi rôznych zúčastnených vlád, ale skutočnosť, že tieto vlády a stav ich súčasných zákonov v tomto ohľade sa neustále menia.
* Moje nahradenie hypertextových odkazov za citácie autorov.
† V článku je predpísaných šesť typov, ale posledné dva nie sú definované.
Prvýkrát publikovaný piatok 7. marca 2025